Membaca HTML Lewat HtmlAgilityPack

HTML-Agility-Pack (HAP) merupakan library yang berfungsi untuk membaca dan menulis Document Object Model (DOM) dari HTML. Library ini akan mentoleransi apabila ada HTML yang ditulis kurang benar. Bagi .NET developer, meng-expose DOM melalui LiNQ-to-XML benar-benar menyederhanakan tugas kita saat meng-explore HTML dengan HAP ini. Kita bisa menggunakan XPATH atau dengan model read seperti XML untuk mencari ke dalam DOM.
Bank Indonesia Kurs
Kalau kita ingin mendapakan list kurs dari Bank Indonesia (BI). Karena BI menggunakan WebForm dengan sharepoint, maka kadang hasil HTML-nya agak berantakan. Key untuk target BI ini adalah table1. Selanjutnya silahkan di baca-baca code di bawah.VB.NET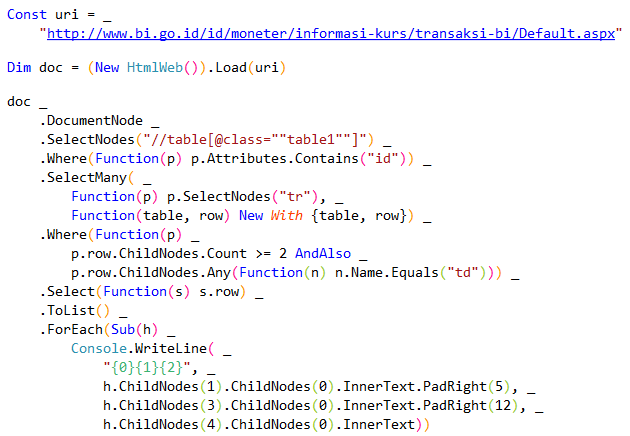
CSharp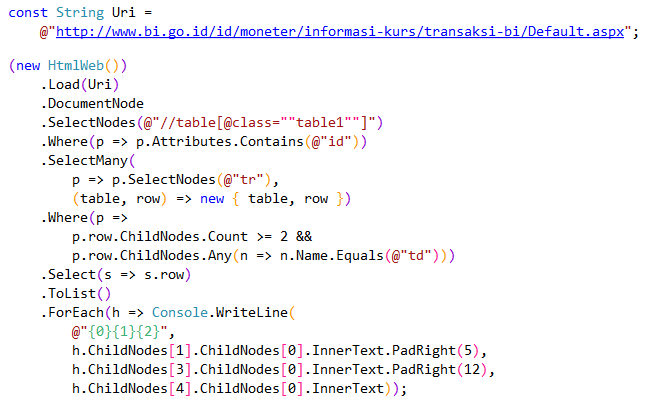
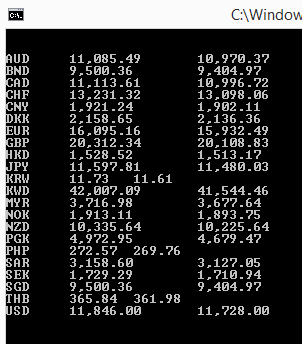
Hasil-nya akan seperti ini
Kaskus User
Untuk mendapatkan informasi dari http://m.kaskus.co.id/profile/ juga cukup sederhana. Cukup kita ambil div yang memiliki c-profile__user-details class seperti gambar di bawah.VB.NET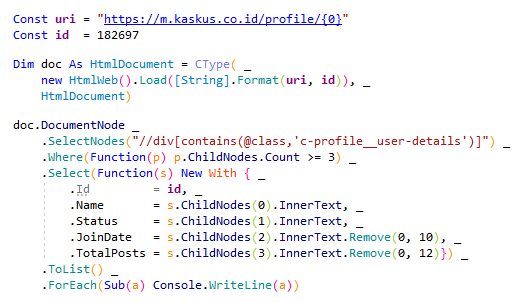
CSharp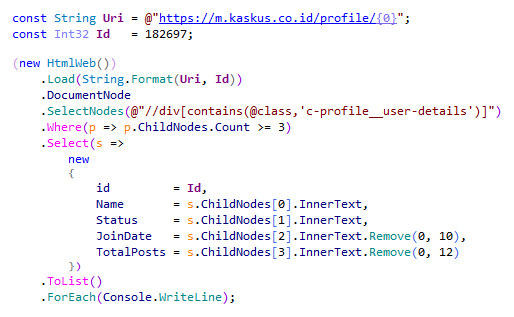
Web Crawler
Mungkin pembaca berfikir untuk melakukan crawler dalam scala besar dengan library ini. Untuk keperluan itu, sebaiknya di pikirkan lagi. Tugas utama library ini adalah parse html.Crawler dalam scala besar memerlukan banyak hal yang perlu dipertimbangkan. Salah satunya, implementasi dari HAP untuk Load dari URL dimaksud untuk pembantu saja dan itu tidak optimal sama sekali serta tidak dapat dikonfigurasi sesuai kebutuhan.
Belum lagi Web Crawler adalah pekerjaan yang I/O Bound memerlukan penanganan berbeda pada saat operasi Parallel. Bicara itu juga, teknik Parallel-nya juga akan berbeda kalau di bandingkan dengan CPU Bound.
Ditambah lagi, bila terlalu banyak request ke sebuah site. Kadang firewall akan menganggap ini sebagai ancaman security. Lagi pula, request http ada limit juga di-OS sehingga perlu di tweak.
Wah repot juga ya? Yup, kalau buat dari awal tentu akan makan waktu dan tenaga untuk buat seperti itu. Untung saja ada yang sudah buat. Coba saja pakai Abot. Walau ada limitasinya untuk basic-binary-nya, pembaca bisa mempelajari source-code dan merubah sesuai dengan kebutuhan.
Untuk meng-crawler-nya kita gunakan Abot dan parse-nya kita gunakan HAP atau library lainnya.
Penutup
Dengan bantuan library HtmlAgilityPack meng-extract sebuah website untuk di ambil informasinya menjadi lebih mudah. Tentu kita juga harus mengerti struktur halaman HTML itu sebelum memulai menggunakan library ini.Referensi
Perhatian! Code yang ditampilkan dalam tulisan ini merupakan ilustrasi dari yang ingin dipaparkan dan bukan production ready code. Sudah banyak kejadian karena asal meng-copy-and-paste tanpa mengerti code yang diambil itu ke dalam production. Selain itu perlu ada tambahan code dan test sebelum siap untuk digunakan secara utuh.


Post a Comment